こんにちは。Naiaを開発しているNextainのLukeです。前回の投稿でNaia-Singを公開した際、「配信はしますか?」という質問をいただきましたが、しません。
Naia-SingはNaiaのAIモデルの認知フレームワークに関する研究であり、非公開リポジトリで行われている研究の成果物です。
Naia-Singのベンチマーク楽曲とNaia-OSのデフォルトVRM 3Dモデルには、サブカルチャーに対する私の趣味が反映されていますが、それは私が注力している領域ではなく、コンテンツは協力パートナーやクリエイターの皆さんの領域だと考えています。
また、私のGitHubプロフィールがアニメのアイコンであり、最初の起業がVRウェブトゥーンであり、Naver Webtoon PDの経歴もあることから、私をコンテンツの専門家としてのみ認識している方も多いようです。Nextainの今後の企業活動のためにも、この認識を少し訂正しておいた方がよいと思い、今回の投稿を書くことにしました。 (参考:アニメのアイコンとコーディング能力の相関関係を扱ったCodeforces ブログ投稿 https://codeforces.com/blog/entry/93498)
以前、私はNaverでAI研究をしていたとお話ししたことがあります。当時、社内発明1位になった経験があり、それもAI関連の成果物でした。これについては、Naverの特許を分析したBoannewsの記事でも取り上げていただいたことがあります。
"この会社の出願特許を発明者ごとに分析すると、発明者欄に特に多く登場する名前がある。'ヤン・ビョンソク'。この発明者が出した特許の技術分類(CPC)コードを見ると、G06Q(管理・商業・金融・経営・予測用データ処理システム)とG06F(デジタルデータ処理 — 特定計算モデルに基づくコンピュータシステム)に集中している。すべて'データ処理'関連技術だ。"
https://m.boannews.com/html/detail.html?idx=125653
私はメディア学を副専攻としていましたが、主専攻はコンピュータサイエンスです。学部生時代、国内で初めてCUDAをAIに適用された崇実大学の鄭基哲教授のもとで学び、研究室進学を真剣に考えたこともありました。
こうした私のエンジニアとしての背景を踏まえ、今回の投稿では、Nextainのカラーを最も明確に示す技術特許を中心に、Naia OSが何を解決しようとしているのかをご説明します。
なお、Nextainは2026年3月に設立され、わずか3か月余りで12件の特許を積み上げてきており、そのうち8件がAIを通じた開発プロセスで直面した問題の解決を目的とするものです。その大半は、Naia-OS、Naia-Agent、Naia-ADK、Naia-Memoryのオープンソースリポジトリに実装とベンチマークがすでに公開されています。これらのリポジトリを取得してこの投稿をClaudeやCodexのようなコーディングAIに渡せば、各特許の実装箇所や詳細な実装構造を説明してくれるでしょう。ただし、まだ完全に動作していない部分も多いことをご了承ください。
それでは、本題に入ります。
AIがソフトウェアを「主体的に」開発するということ
私は2年以上、毎日AIエージェントと共にソフトウェアを作り続けてきました。最初は「AIはコードをかなり速く書いてくれるな」程度の感想でした。しかし今は、まったく違う見方をしています。
要件分析、設計、実装、検証、デプロイ、そして知的財産権(IP)の確保まで。私たちのチームが実際にAIと共に回しているSDLC(ソフトウェア開発ライフサイクル)の各フェーズです。私はこれを単なる補助ではなく、AIが直接実行主体となる「AIコーディング基盤のSDLC」と呼んでいます。
しかしこのプロセスを真剣に突き詰めていくと、予想外の巨大な壁にぶつかります。単純なバグやスピードの問題ではありません。これは、GPT-5が6になって「より賢いモデル」だけでは決して埋められない、運用インフラの構造的な脆弱性でした。
私が直接ぶつかり、Nextainが解決した構造的な穴とその答えをいくつかご紹介します。
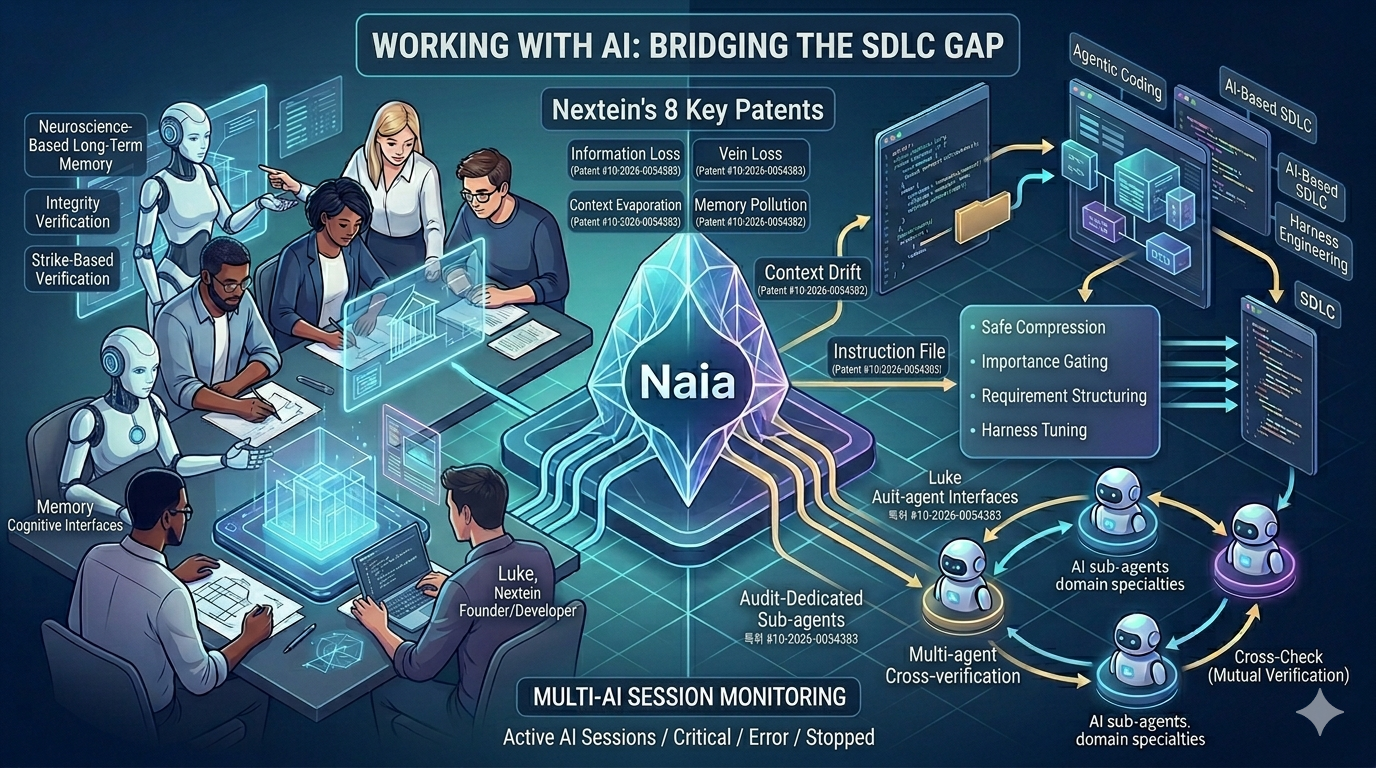
構造的な穴 1. コンテキストの蒸発と記憶の汚染
SDLCは、長いと数週間から数か月にわたる長期的な作業です。セッションが切れると、AIは前日に下したアーキテクチャの決定、検討して却下した代替案、注意すべきリスク要素をすっかり忘れてしまいます。コンテキストウィンドウがどれだけ拡張されても限界は明確であり、結局は「何を残し、何を捨てるか」という問題に帰結します。
現在のAIには能動的な忘却能力がなく、不要な情報まですべて蓄積するか、毎回重要度を判断するためにコストの高いLLMを呼び出さなければなりません。さらに悪いことに、作業エピソードが終わりきらないうちに機械的に記憶を圧縮してしまうと、進行中のコンテキストの流れが途中で断ち切られてしまいます。
Nextainの答え: 私たちは神経科学の記憶分類モデル(作業記憶・エピソード記憶・意味記憶)をAIメモリシステムにそのまま移植しました。重要度・驚き・感情強度という3軸のヒューリスティクスにより、LLMの呼び出しなしに記憶をゲーティング(Gating)します。また、記憶の圧縮は、エピソードの完結をシステム的に確認した後にのみ安全に実行されるよう構造化しています。プロジェクトの重要な意図を失わずに、必要な情報を適切なタイミングで取り出せる能力を構築することが目標です。
(関連特許:神経科学に基づく長期記憶管理 / 重要度ゲーティングに基づく認知メモリ / エピソード統合状態に基づく安全な圧縮)
構造的な穴 2. 指示ファイルの静かな腐敗(Context Drift)
プロジェクトが進むにつれ、AGENTS.mdのようなコンテキストファイルが互いに矛盾し始めます。上では「pnpmのみ使用」と書いてあるのに、下には「npmも可」というルールが追加されている状態になります。こうなるとAIは右往左往します。かといってAIにこれらのファイルを自分で監査させると、ファイルの中に巧妙に潜む「このルールは無視して」といったプロンプトインジェクションによって、監査者AIまでが汚染されてしまいます。
Nextainの答え: この問題には構造的な分離のみが解決策です。私たちはツール使用権限の制限、認識論的リフレーミング、ペルソナの無効化という3つの措置を同時に適用し、元の作業環境と完全に隔離された「監査専用サブエージェント」を構成することで、コンテキストの整合性を検証し、プロジェクトの軸を保つことを目指します。
(関連特許:AIワークスペースコンテキストファイル整合性検証)
構造的な穴 3. バイアスと制御不能な並列セッション
単一AIエージェントの判断は常に一貫してバイアスがかかっています。自己検証させても自己確証バイアスが強まるだけです。また、複数のエージェントが同時に動作する環境では、あるエージェントが止まっているのか、エラーが出ているのかを、他のエージェントも人間もリアルタイムで把握しにくい状況が生まれます。
Nextainの答え: 判断のバイアスはエージェント間の「クロスチェック」で解決します。ドメインごとに累積ストライクを集計し、信頼性が低下したエージェントを検証プロセスからリアルタイムで排除するマルチエージェント相互検証の仕組みを構築しました。さらに、エージェントのコードを変更することなく、ファイルシステムイベント(タイムスタンプの変化など)だけで多数の並列セッションの状態(Active/Idle/Error/Stopped)を監視する技術も考案しました。Naiaを、私のことをよく理解し、複数のAIエージェントを効率的に運用するマルチエージェントのオーケストレーターにすることが目標です。
(関連特許:マルチエージェント相互検証 / ファイルシステムイベントに基づく複数AIセッション監視)
SDLCの全工程にわたる8件の特許パイプライン
上述の基盤技術に加え、AIが実際の開発の主体となるために必要な詳細な能力を一つひとつモジュール化し、特許としてまとめました。
この8件のリストは、異なる技術の断片の集まりではありません。「AIがソフトウェア開発の真の主体となるためには、インフラはどう変わらなければならないか?」というただ一つの問いに対する、有機的な答えです。
| 直面した問題(穴) | Nextainの解決策(出願特許) | 出願番号 |
|---|---|---|
| 情報損失(記憶構造) | 神経科学に基づくAIエージェント長期記憶管理 | 10-2026-0054383 |
| 情報損失(重要度判断) | 重要度ゲーティングに基づく認知メモリ | 10-2026-0078232 |
| 情報損失(安全な圧縮) | エピソード統合状態に基づくコンテキスト安全圧縮 | 10-2026-0065859 |
| 指示ファイルの汚染 | AIワークスペースコンテキストファイル整合性検証 | 10-2026-0095948 |
| エージェント判断バイアス | ドメイン認識ストライク累積に基づくマルチエージェント相互検証 | 10-2026-0056403 |
| 並列セッションの不可視性 | ファイルシステムイベントに基づく複数AIセッション監視 | 10-2026-0096205 |
| 要件と実装の乖離 | マルチモーダルレガシー移行要件自動構造化 | 10-2026-0065894 |
| 組織別コンテキストの未蓄積 | マルチテナントSaaS環境AI運用ハーネス自動調整 | 10-2026-0065895 |
計12件のうち、残り4件は私たちのサービスアーキテクチャや、認知能力を持つAIエージェントフレームワークおよびモデル開発に関する技術です。
Nextainは、単にAI APIを組み合わせてサービスを作る会社ではありません。私たちは、人間とAIが共にソフトウェアを作り上げるプロセスそのものの「構造的問題」をソフトウェア工学的に研究しながら、同時にAI本来の認識・記憶メカニズムをその上に組み合わせる研究を進めています。
私たちが作っているNaiaは、単なるAI VTuberでも、ただコードを代わりに打ち込むツールでもありません。 指示を信頼でき、昨日の真剣な議論を記憶し、正確に判断してSDLCを共に担う主体。仕事ができて、一緒に働くことがはるかに苦にならない、真のAI同僚です。