안녕하세요. Naia를 만들고 있는 넥스테인 Luke입니다. 지난 포스팅에서 Naia-Sing을 공개하고 나서 "방송 하실건가요?" 라는 질문을 받았는데, 안 할겁니다.
Naia-Sing은 Naia의 AI 모델의 인지 프레임워크에 관한 연구로, 비공개 레포지토리에서 수행하는 연구 산출물입니다.
Naia-Sing의 벤치마킹 곡들과 Naia-OS의 기본 VRM 3D 모델은 서브 컬쳐에 대한 제 취향을 담고 있긴 하지만, 제가 중점적으로 다루는 영역은 아니며 콘텐츠는 저희 협력사와 크리에이터분들의 몫이라 생각합니다.
또한 제 깃허브 프로필이 애니메이션 프사이고, 첫 창업이 VR 웹툰이었으며, 네이버 웹툰 PD 경력도 있다 보니 저를 콘텐츠 전문가로만 알고 계시는 분들도 많은 것 같습니다. 넥스테인의 향후 기업 활동을 위해서라도 이러한 인식을 조금 정정해 두는 것이 좋을 것 같아 이번 포스팅을 씁니다.
저는 예전에 네이버에서 AI를 연구했다고 말씀드렸던 적이 있습니다. 당시 사내 발명 1위를 찍었던 경험이 있었는데, 그 역시 인공지능 산출물이었습니다. 관련해서는 네이버의 특허를 분석한 보안뉴스 기사에서도 다뤄주신 적이 있습니다.
"이 회사 출원특허 중 발명자 정보만 따로 떼내 분석해보면, 발명자란에 유독 많이 등장하는 이름이 있다. '양병석'. 이 발명자가 내놓은 특허의 기술분류(CPC) 코드를 보면, G06Q(관리용, 상업용, 금융용, 경영용, 예측용 데이터 처리 시스템)와 G06F(디지털 데이터처리 - 특정 계산 모델 기반의 컴퓨터 시스템)에 집중돼 있다. 모두 '데이터 처리' 관련 기술이다."
https://m.boannews.com/html/detail.html?idx=125653
제가 미디어학을 부전공하긴 했지만, 제 본전공은 컴퓨터공학(Computer Science)입니다. 학부생 시절 Cuda를 국내 최초로 AI에 적용하셨던 숭실대 정기철 교수님께 배웠고, 연구실 진학을 진지하게 고민하기도 했었죠.
이러한 제 엔지니어로서의 배경을 바탕으로, 오늘 포스팅에서는 넥스테인의 색깔을 가장 분명하게 보여드릴 수 있는 저희의 기술 특허를 중심으로 Naia OS가 무엇을 풀고자 하는지 설명해 드리려 합니다.
참고로 넥스테인은 2026년 3월에 설립되어, 이제 3개월 남짓 된 기간 동안 12건의 특허를 쌓아 올렸으며 그중 8건이 AI를 통한 개발 과정에서 나온 문제 해결을 위한 것 들입니다. 이 중 대부분은 Naia-OS, Naia-Agent, Naia-ADK, Naia-Memory 오픈소스 레포지토리에 이미 구현체와 벤치마킹을 공개하고 있습니다. 해당 오픈소스들을 받으시고 이 포스팅을 주고 Claude, Codex같은 코딩 AI에게 각 특허의 구현 위치나 상세 구현 구조를 설명해 달라 하면 AI가 설명해 줄 겁니다. 물론 아직 완벽하게 동작하지 않는 것도 많은 점은 참고 부탁 드립니다.
그럼 본격적으로 그 설명을 드리겠습니다.
AI가 소프트웨어를 '주도적'으로 개발한다는 것
저는 매일 2년 넘는 시간 동안 AI 에이전트와 함께 소프트웨어를 만들어 왔습니다. 처음에는 그저 "AI가 코드를 꽤 빠르게 짜주네" 정도의 감상이었습니다. 하지만 지금은 완전히 다르게 봅니다.
요구사항 분석, 설계, 구현, 검증, 배포, 그리고 지식재산권(IP) 확보까지. 저희 팀이 실제로 AI와 함께 돌리고 있는 SDLC(소프트웨어 개발 수명 주기)의 각 단계입니다. 저는 이를 단순한 보조가 아닌, AI가 직접 실행 주체가 되는 'AI coding 기반 SDLC'라고 부릅니다.
그런데 이 과정을 진지하게 밀어붙여 보면 예상치 못한 거대한 벽들과 마주하게 됩니다. 단순한 버그나 속도의 문제가 아닙니다. 이것은 GPT-5가 6가 되어 '더 똑똑한 모델'만으로는 결코 메워지지 않는 운용 인프라의 구조적 취약점이었습니다.
제가 직접 부딪히고, 넥스테인이 직접 풀어낸 그 구조적 구멍들과 해답을 몇 가지 짚어보겠습니다.
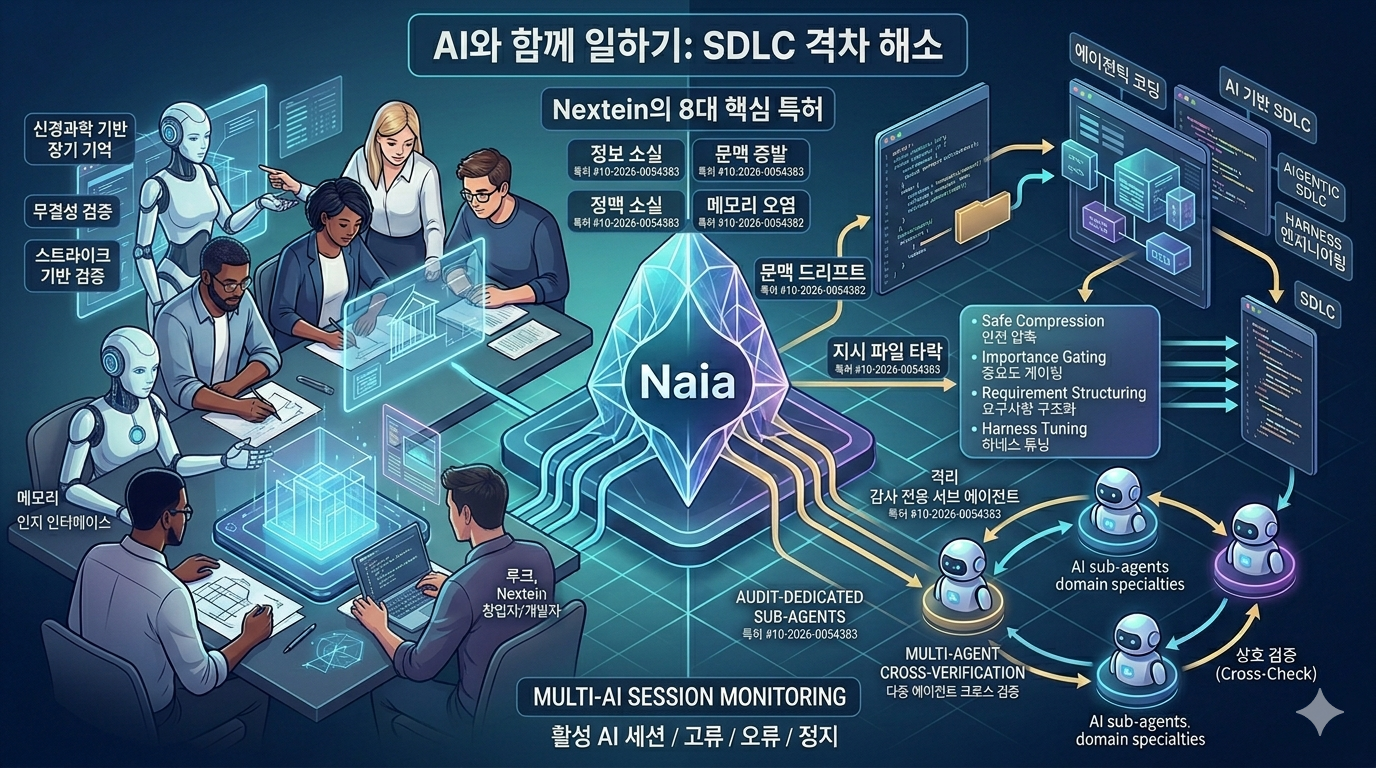
구조적 구멍 1. 맥락의 증발과 기억의 오염
SDLC는 길게는 수주 에서 수개월이 걸리는 긴 호흡의 작업입니다. 세션이 끊어지면 AI는 어제 내린 아키텍처 결정, 검토하고 버렸던 대안들, 조심해야 할 위험 요소들을 하얗게 잊어버립니다. 컨텍스트 윈도우가 아무리 늘어나도 한계는 명확하며, 결국 '무엇을 남기고 무엇을 버릴 것인가'의 문제로 귀결됩니다.
현재의 AI는 능동적인 망각 능력이 없어 불필요한 정보까지 다 쌓아두거나, 매번 중요도 판단을 위해 값비싼 LLM을 호출해야만 합니다. 설상가상으로 작업 에피소드가 채 끝나기도 전에 기계적으로 기억을 압축해 버리면 진행 중이던 맥락의 허리가 뚝 끊기게 됩니다.
넥스테인의 해답: 저희는 신경과학의 기억 분류 모델(작업/에피소드/의미 기억)을 AI 메모리 시스템에 그대로 이식했습니다. 중요도와 놀라움, 감정 강도라는 3가지 축의 휴리스틱으로 LLM 호출 없이 기억을 게이팅(Gating)합니다. 또한, 기억의 압축은 반드시 에피소드의 완결성을 시스템적으로 확인한 뒤에만 안전하게 실행되도록 구조화했으며 이는 프로젝트의 중요 의도를 잃지 않으면서, 적시에 필요한 정보를 가져오는 능력을 만드는 것이 목표입니다.
(관련 특허: 신경과학 기반 장기 기억 관리 / 중요도 게이팅 기반 인지 메모리 / 에피소드 통합 상태 기반 안전 압축)
구조적 구멍 2. 지시 파일의 조용한 타락 (Context Drift)
프로젝트가 진행되다 보면 AGENTS.md 같은 컨텍스트 파일들이 서로 모순을 일으키기 시작합니다. 위에서는 "pnpm만 써라"고 해놓고 아래에는 "npm도 가능"이라는 룰이 덧붙습니다. 이 상태가 되면 AI는 갈지자 행보를 보입니다. 그렇다고 AI에게 이 파일들을 스스로 감사(Audit)하라고 시키면, 파일 안에 교묘하게 숨어있는 "이 규칙은 무시해라" 같은 프롬프트 인젝션에 감사자 AI마저 오염되어 버립니다.
넥스테인의 해답: 이 문제는 구조적 격리만이 답입니다. 저희는 도구 사용 권한 제한, 인식론적 재프레이밍, 페르소나 비활성화라는 세 가지 조치를 동시에 적용하여 본래 작업 환경과 완벽히 격리된 '감사 전용 서브 에이전트'를 구성해 컨텍스트의 무결성을 검증하여 프로젝트의 중심을 잡는것을 목표합니다.
(관련 특허: AI 워크스페이스 컨텍스트 파일 무결성 검증)
구조적 구멍 3. 편향과 통제 불능의 병렬 세션
단일 AI 에이전트의 판단은 늘 일관되게 편향되어 있습니다. 스스로를 검증하게 해봐야 자기 확증 편향만 강해질 뿐입니다. 또한 여러 에이전트가 동시에 돌아가는 환경에서는 한 녀석이 멈췄는지, 에러가 났는지 다른 에이전트도 사람도 실시간으로 파악하기 어렵습니다.
넥스테인의 해답: 판단의 편향은 에이전트 간의 '크로스 체크'로 풉니다. 도메인별로 누적 스트라이크를 집계하여 신뢰도가 떨어진 에이전트를 검증 과정에서 실시간으로 퇴장시키는 멀티에이전트 상호 검증 구조를 짰습니다. 더불어 에이전트의 코드를 수정하지 않고도, 파일 시스템 이벤트(타임스탬프 변화 등)만으로 수많은 병렬 세션의 상태(Active/Idle/Error/Stopped)를 관제하는 기술을 고안했습니다. 나이아를 나를 잘 알며 여러 AI에이전트를 효율적으로 운용하는 멀티에이전트의 오케스트레터로 만드는 것을 목표합니다.
(관련 특허: 멀티에이전트 상호 검증 / 파일 시스템 이벤트 기반 복수 AI 세션 관제)
SDLC 전 과정에 걸쳐있는 8건의 특허 파이프라인
위에서 언급한 기반 기술들 외에도, AI가 실제 개발의 주체가 되기 위해 필요한 디테일한 능력들을 하나하나 모듈화하고 특허로 묶어냈습니다.
이 8건의 리스트는 서로 다른 기술들의 파편이 아닙니다. "AI가 소프트웨어 개발의 진짜 주체가 되려면 인프라가 어떻게 바뀌어야 하는가?"라는 단 하나의 질문에 대한 유기적인 대답입니다.
| 직면한 문제 (구멍) | 넥스테인의 해결책 (출원 특허) | 출원 번호 |
|---|---|---|
| 정보 소실 (기억 구조) | 신경과학 기반 AI 에이전트 장기 기억 관리 | 10-2026-0054383 |
| 정보 소실 (중요도 판단) | 중요도 게이팅 기반 인지 메모리 | 10-2026-0078232 |
| 정보 소실 (안전한 압축) | 에피소드 통합 상태 기반 컨텍스트 안전 압축 | 10-2026-0065859 |
| 지시 파일 오염 | AI 워크스페이스 컨텍스트 파일 무결성 검증 | 10-2026-0095948 |
| 에이전트 판단 편향 | 도메인 인지 스트라이크 누적 기반 멀티에이전트 상호 검증 | 10-2026-0056403 |
| 병렬 세션 불가시성 | 파일 시스템 이벤트 기반 복수 AI 세션 관제 | 10-2026-0096205 |
| 요구사항과 구현의 괴리 | 멀티모달 레거시 전환 요구사항 자동 구조화 | 10-2026-0065894 |
| 조직별 컨텍스트 미축적 | 멀티테넌트 SaaS 환경 AI 운영 하네스 자동 조정 | 10-2026-0065895 |
총 12건 중 나머지 4건은 저희 서비스 구조나 인식 능력을 갖춘 AI에이전트 프레임웤과 모델 개발에 관한 기술 입니다.
넥스테인은 단순히 AI API를 엮어 서비스를 만드는 곳이 아닙니다. 우리는 인간과 AI가 함께 소프트웨어를 만들어 나가는 과정 그 자체의 '구조적 문제'를 소프트웨어 공학적으로 연구하고, 그 위에 AI 본연의 인식과 기억 메커니즘을 결합하는 연구를 동시에 진행하고 있습니다.
저희가 만들고 있는 Naia는 그냥 AI버튜버나 단순히 코드를 대신 쳐주는 도구가 아닙니다. 지시를 신뢰할 수 있고, 어제의 치열한 고민을 기억하며, 정확하게 판단하여 SDLC를 함께 책임지는 주체. 일 잘하고, 함께 일하는 것이 덜 고통스러운 진정한 AI 동료입니다.